
DataWorks Summit 2017 - Munich - Part 1
April 4th, 5th and 6th 2017, Munich, Germany hosted DataWorks Summit (or as previously called Hadoop Summit). This is a conference organized by Hortonworks and Yahoo. It's about Hadoop, Big Data and Open Source community.
This year I've had a chance to be there for the first time and figured I will share my thoughts about the event and things around it.
I have arrived on Tuesday, 4th April, one day before the conference starts but there were some unoficial events that day too. You could have taken one of the trainings or came to several meetups organized by speakers of the event.
Anyway, for all of you traveling to Munich for the first time. If you happen to get out of your plane and instead of walking into baggage claiming area you are entering the shopping and restaurant zone, don't be worried, that's how it is there ... Your bagge is there somewhere, it's just that somewhere happens to be at the other end of the airport. You have to take a train to get it. I may have not visited a lot of big airports in my life yet, but I have seen few and this was first time I've seen it :) But it could be true (and most probably is) only for the terminal I used, so your expeirence may vary.

But let's focus on the main topic. Tuesday was meetups day as I mentioned. There were few of them:
- Accelerating Apache Big Data and Machine Learning Workloads on OpenPOWER
- Big Data in Automotive
- Tensorflow and Hadoop, Accelerating HBase & Using BigBench to compare Hive and Spark
- Cloud – Running and Securing Hadoop in the Cloud
- SAS and Spark on HDP
- Solving Cybercrime at Scale and in Realtime

I went to the SAS and Spark on HDP which happend to be Spark on HDP as the SAS speaker couldn't make it. Meetup was hosted by Bernhard Walter and Aengus Rooney of Hortonworks. We went through history and how all that data science in a distributed way started. For all of you not that much into hadoop and Spark in particular. The whole fuss about it is not because spark has some extra powerfull algorithms that are not seen in different libraries, it's because Spark works in a distributed way. That means you are not limited to your PC or Server computing power or amount of RAM you have there.
In fact while Spark is definitelly good at selection of Machine Learning algorithms (MLib), there are betters. But for large scale computations where your training set is large, having possibility to train the model on a cluster of machines is what made it so popular. Of course Spark is not only about ML, but the reasoning still holds. If you have large dataset it is better to compute it having more RAM and CPU at your disposal.
Anyway, Bernhard and Aengus went through the example of building recommendation model based on last.fm dataset that was released sometime in 2015 with arround 1.8 million of artits. Really interresting panel with quick introduction how you can build that in Spark and what are best practices in setting hyperparamethers for instance. How should we use existing data for training and cross validation.
BTW, did you know most people listen to 160 artists only?
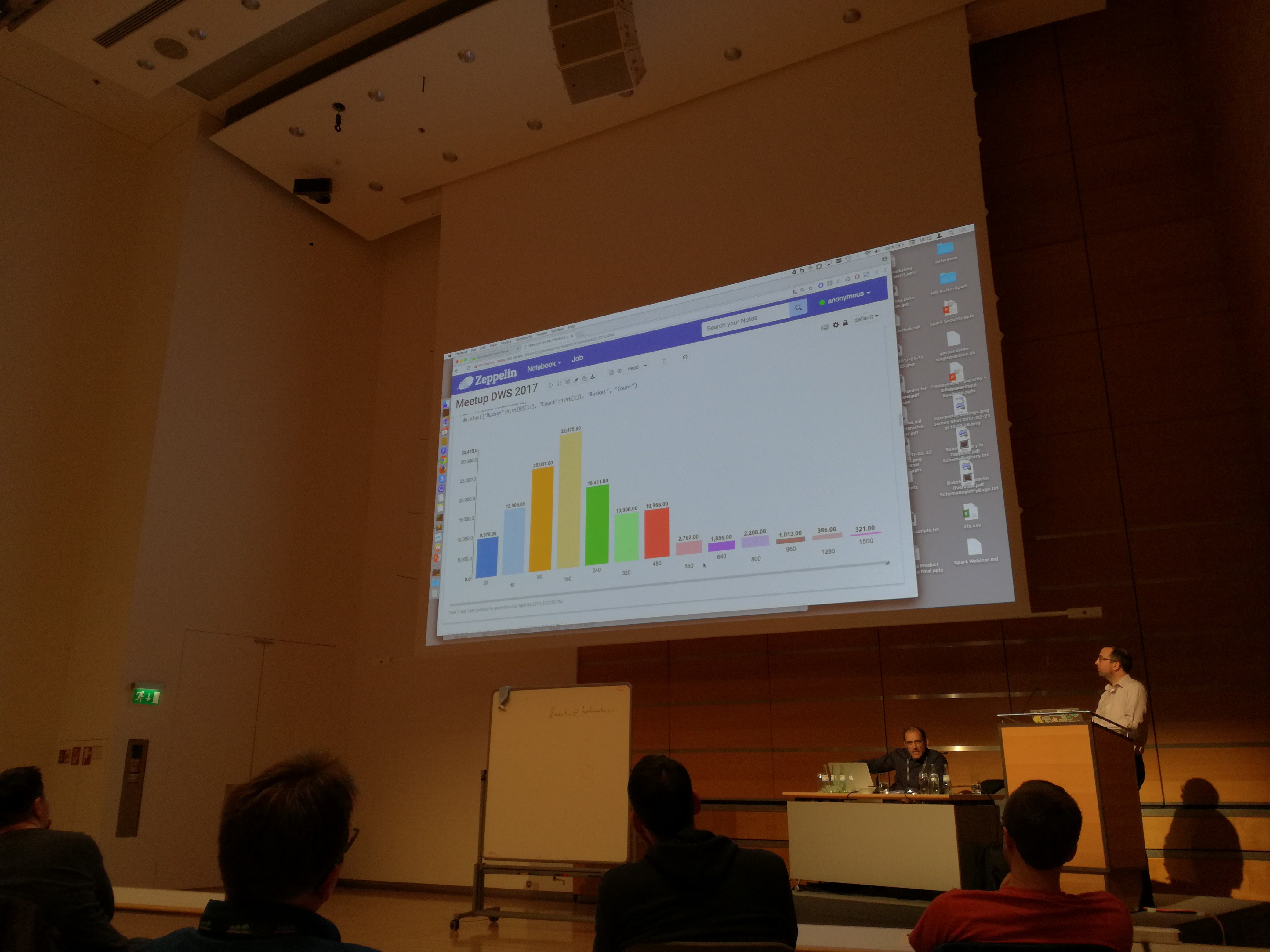
I mentioned where Spark wins and why, but if the dataset is small, then often it is better to switch to something else like numpy. Like when guys showed how they checked how many false hits their model produces. We know the exact list of artists each user listens to, we have created a model that predicts what would they like to listen to. We can check the model by running it on a subset of users and look for recommendations of artists they never listen to. Dataset for that one had only 1500 rows, and it was easier to run it locally using numpy.
We haven't discussed what next if truth be told, I mean once you have your perfect model what are best scenarios to deploy them in production. We may want to have dedicated post about it sometime in future though.
OK. So that was first day. The summit official start date was Wednesday though at 8AM with breakfast.
At 9AM it really kicked off with a Keynote and pretty amazing laser show :). This kind of fireworks are common for EMC from my experience, apparently Hortonworks is into it a little too ;) Well, there were no dancers so EMC wins there. But most important was the content of course.
As one can expect, keynote is for highlevel panels, it's also time for sponsors so nothing very exiting, but one speaker got my full attention and I must say I really liked his panel. It seems that organizers wanted to make sure not everything panels are technical / business. They invited few speakers who focus on ethical side of Data Driven society. The particular panel was held by Dr Barry Devlin.
In times when AI gets so much better ar interacting, reading context and running processes, we should expect more and more problems due to the fact manual labour but also high profile labour will no longer be needed. Dr Devlin says new approach to handling this kind of issues is needed and guaranted income for everyone is one of them. If you have a chance to watch his speach - definitelly do.

During keynote a panel with experts took place too. Most interresting thing I remember from it is what Daljit Rehal of Centrica said about how the work culture changed in his company. Data driven projects are very demanding in terms of skilled engineers. At Centrica some cultural changes had to take place so that employees can focus on actuall work instead of figuring out how they should do that work. Motivation for self development is also a key factor. So the approach changed from centrally managed environment to more people centric approach. For instance if you work at Centrica and already has preffered language you code in, if only it can be used - you are free to do it. I am aware this is not always possible but in project so much oriented on Open Source solutions, this is very much possible and most probably the only way to go. As for motivating people for self development. Engineers at centrica are encourages to give lectures at local Universities which gives them strong motivation factor to be prepared I suppose ;)
You can watch the keynote here.
Technical and business sessions were held in 6 different rooms simultaneously. This was the toughest part of the summit, how on earth are you suppose to choose if most of them are equally interesting?
Good thing about DWS is that most if not all session will be available on YouTube, so you can catch up with those you missed. I strongly encourage you to do so.
In next part I will sunmmarize some of the sessions I have watched and think were most interesting ones. I think some of them will lead to separate posts related to what was shown on that sessions. So stay tuned for more!
And go and check DataWorks Summit videos that are posted on Youtube
mrc