
DataWorks Summit 2017 - Munich - Part 2
In part 1 I have summarized keynote and its most interresting parts, in part 2 I will summarize some of the session I found most interessting.
Again, there were many more at least as entertaining, check the DataWorks Youtube channel for them.
Interactive Analytics at Scale in Apache Hive using Druid
If you need to create and then publish dashboards that are built on large amount fo data, then Druid is something you may want to check on. One use case would be for data that you prepare in Spark and then publish in Druid. The advantage of Druid compared to SparkSQL is latency. Druid indexes all its data. So if you need to create visualization layer in your company with large amount of people using it, have a look.
For more information and a benchmark that compares Druid to Spark, have a look at this post of Harish Butani. And you can watch the session recording here
Streaming Analytics Manager
This is something that I'd like to play around definitelly. You should expect dedicated article some time on the future.
SAM - among others - is a graphical tool that lets you build whole streaming process without need to write a code. Most importantly if at any moment in time schema changes at any place in your process, adjusting it is honestly really easy. Normally you'd have to change code, here you have everything accessible from nice GUI.
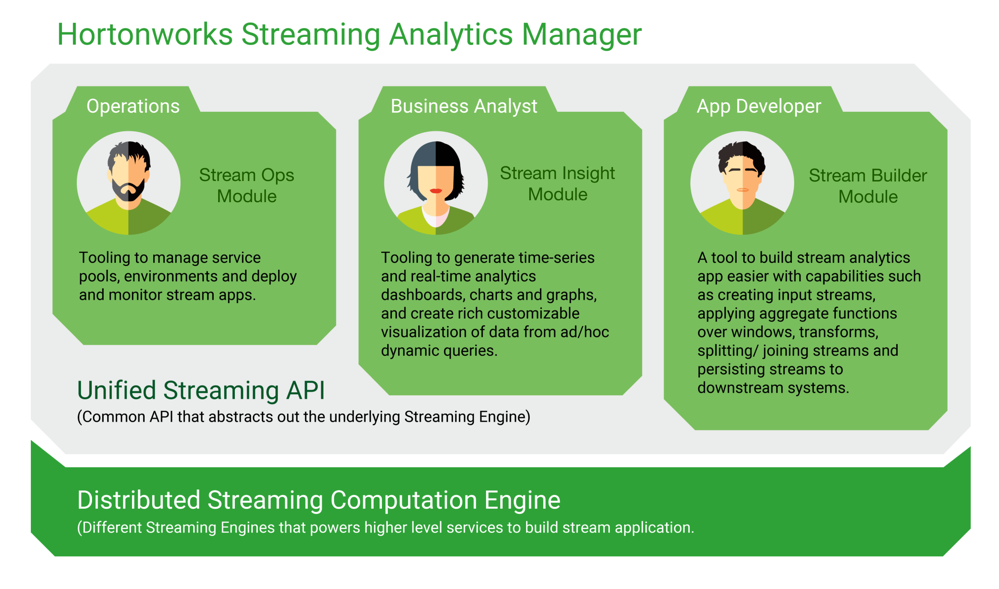 Source: https://hortonworks.com/info/streaming-analytics-manager/
Source: https://hortonworks.com/info/streaming-analytics-manager/
On top of that, you have access to all your streaming data and even some metrics in one single graphical tool. If you are into streaming, watch the session recording as soon as it is up on Youtube (I'll add the link then).
This is not yet production ready mind you.
Machine Learning in Healthcare
Some of the session were not about particular tools, new releases, new functionalities. They were about real life examples how Big Data Technologies helped or allowed for businesses to grow or helped scientists or doctors be more precise and much faster in their work.
One of that session was held by Wade Schulz, Physician Scientist and Clinical Pathology Resident at Yale School of Medicine. Wade is also lead architect of Big Data platform at mentioned School that also operates one of the largest hospitals in US, Yale-New Haven Hospital.
He gave an example of how they learned to use that possibilities of new technologies. One of the most often laboratory test made in hospitals around the world is peripheral blood smear. Blood sample is put on a glass and checked using microscope. Depending on anomalies found a diagnose could be made. Normally tests are subject to human eye perceptivity and its owner experience. In a hospital such as this there are hundreds of those tests made daily. Due to its nature it requires a lot of personel and time to be involved.

Dr Schulz and his team work on a Machine Learning model that will analyse images of monolayer containing the tests data. It is now during acceptance tests of sort but already is much more accurate and much faster than current way of doing the tests. Eventually approval by a physician may still be needed to accept the result of an algorithm, but even then the gains could be significant. Mostly in terms of time needed for tests results and that can lead to more lifes saved.
Each new technologies can be used for bad or good thing. This definitelly is an example of the later.
I wonder if similar research is done at any European hospitals or Laboratory centers. If you know about any, please let us know!
Watch the session here.
Real-Time Anomaly Detection Using LSTM Auto-Encoders with DeepLearning4J on Apache Spark
Session was held by Romeo Kienzler of IBM. Topic is very on time, the panel was about Machine Learning, well it's subclass in fact - Deep Learning, it was about IoT too, which is the next big thing in IT. I know, we have heard that for many years now... The thing is, technology seems to be now at the level that actually allows for this to grow to its real potential.
Romeo explained Deep Learning concepts, so we had a quick recap of Neural Networks, how they work and how they are used in Deep Learning.
Deep Learning is good at solving mathematical problems, not so much at recognizing sequences, and that is big thing of IoT, where Time based sequences are rather very common.
This is where LSTM comes handy.So Long Short Term Memory adds memory, long term memory in fact to neural networks. Thanks to that you can recognize and process sequences.
One example shown was where algorithm was teached using Shakespir literature and then it could write poems ;). Or when algorithm was teached to write C code like text ^^.
The main topic was Anomaly Detection though. If you're into it, watch the video! One example I can think of using this would be for instance for power grids. Normally, power consumption is something we can predict. There are very simillar trends based on what day of a week it is, what time and what season. I can think of using Deep Learning and LSTM in particular to build very good anomaly detection model that can alert the maintenance teams of something unexpected happening.
Other example, if you manage Data Center systems, storage for instance, there would be some trends there too. Would be interesting to see if we can use this to detect anomalies which could help finding out something happens to the infrastructure. This can be also used for forecasting and in storage area - as an example - it could be a real help for all of you trying so hard to determine what is the best oversubscription policy and when you should buy additional disks. You can watch the recording of the session here.
Hops Hadoop and its HSFS (Hops FS) performance
One of the thoughts I have had after the conference was that USA is really ahead of Europe in Data world. It really looks like it. I supose we will catch up sooner or later hopefully, nevertheless for now we are lagging behind.
Hops Hadoop is one example where an European project found a spot for itself. Hops is the only European Hadoop distribution apparently.
Jim Dowling of KTH Royal Institute of Technology in Stockholm shows new approach for Namenodes architecture. If you're into Hadoop world you must have thought about it before and things are kind of tricky with Namenode in HDFS. You can read more about it here.
So HopsFS reengineered NameNode from scratch while maintaining almost 100% compatibility with standard HDFS clients. Instead of keeping all metadata in memory, checkpoints in fsimage and recent changes in edit log they keep all that data in MySQL in memory Database Cluster that is build with a distributed approach. That means HSFS clients can write to HSFS in pararell. This is not the case with standard HDFS architecture, where each write operation triggers system wide lock that prevents more than one write operation to happen at a time.
This seems to have quite significant impact on performance in large clusters. Please watch the video for benchmark data and examples, but if you use large cluster and HDFS performance is a problem for you, this might be something you want to try as Spotify did aparently. I wonder thugh if they still use it, from what I know they have moved to Google Cloud (or are being in the process of tranistion).
One last comment, apart from performance, amount of medatada you can store with HSFS is much higher. In HDFS there is upper limit due to the fact all that data needs to be keept in JVM memory.
Summary
I have seen more sessions, plan to watch even more on Youtube. And you will see dedicated posts about some of the concepts and tools which are not described in this article.
A good summary for this year DataWorks Summit may be the fact that a lot of use cases, real life examples and development seem to go toward streaming and IoT technologies. Batch processing will be taken over by streaming quite soon Laregely due to IoT and there, automotive seem to be the main actor.
BMW and their Big Data Team lead held a session about they're journey, where they are and what still needs to be done. Especially given the fact they are part of big international organization where processes makes some things happen slower than at a startup for instance. Anyway, the message was clear. BMW sells almost 2 millions cars each year. Each of them is now "connected". This is huge amount of data to tranfer, store and anlyze. Cars soon will not only send data to central, they will communicate with each other and with the surroundings. Their sensor will (and some already are) use advanced AI algorithms to drive the cars by themselves. This all will be possible thanks to development in Big Data technologies.

Tobias Buerger who gave that speach shared also experience he and his team had and what are their lessons learned. I can only recommend to watch his pannel so much to every team leads, managers and CTOs who have something to do with new technologies, Big Data in particular. Some of the most important experience they have (that's something so obvious it's hard to imagine someone would not know it, and yet...) were:
- Make sure you have a great team! From my own experience too, yes, this is important, so much, really.
- Be prepared for immaturity. In so dynamic environment as anything related to Big Data - yes. Don't expect enterpise grade, production ready everything. Sometimes you may need to choose between environment tested for years that will need a month to analyze your data and environment which may not have that much maturity, but will perform the analysis in 5 minutes. The choice is yours.
- Be prepated for pitfalls, it happens.
mrc